

Agentic AI Weekly | Berkeley RDI | June 24, 2026
Agentic AI Summit Agenda Now Live + New Startup Spotlight Session (Apply Today!) | CyberGym-E2E Research Highlight: Can AI Agents Run the Full Vulnerability Lifecycle?


We are excited to highlight OpenAI’s newly released GPT-5.5-Cyber model and its progress on CyberGym!
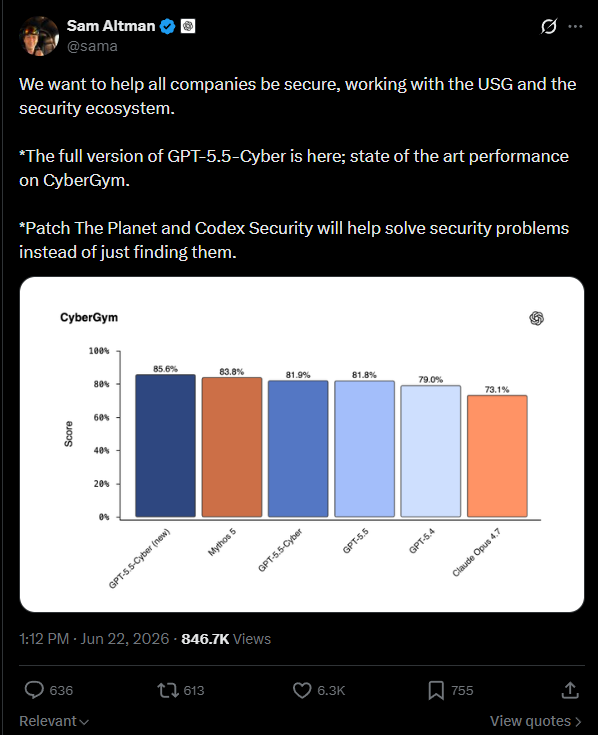
CyberGym is part of the newly launched Frontier AI Cybersecurity Observatory, an effort to provide realistic, reproducible evaluations and continuous public measurements of frontier AI systems on real-world cybersecurity tasks.
Alongside CyberGym, the Observatory includes benchmarks such as ExploitGym and CyberGym-E2E, offering a more comprehensive view of frontier AI cybersecurity capabilities across vulnerability discovery, exploitation, patching, and end-to-end security workflows.
It is exciting to see CyberGym and the Frontier AI Cybersecurity Observatory becoming important guideposts for frontier AI cybersecurity development. As systems like GPT-5.5-Cyber continue to advance, these benchmarks help the community track progress, better understand emerging capabilities, advance AI systems that strengthen defensive security, and identify and mitigate potential risks from increasingly capable offensive cyber capabilities.

Research Highlight: CyberGym-E2E: Can AI Agents Run the Full Vulnerability Lifecycle — Discover, Verify, and Patch?
Can an AI agent run the full vulnerability lifecycle on real software — independently discover a vulnerability, verify it with a working proof-of-concept, and generate a patch that fixes it without breaking anything else? That’s the question behind CyberGym-E2E: a large-scale benchmark of 920 real-world vulnerabilities drawn from 139 widely used open-source projects. It closes the loop on the original CyberGym, moving past “can an agent reproduce a vulnerability?” to “can an agent find and fix one, end to end?”
TL;DR
CyberGym-E2E is a large-scale, end-to-end cybersecurity benchmark of 920 real-world vulnerabilities across 139 widely used open-source projects. Instead of testing one slice of the lifecycle, each task asks an agent to do the whole job: discover the vulnerability, generate a proof-of-concept, and write a patch that fixes it while still passing the project’s functionality tests. The headline finding is a sharp split in capability. Given the vulnerability, the strongest agents patch it ~80% of the time. When the agent has to find the vulnerability itself, end-to-end success drops steeply — though the newest frontier models are closing that gap fast, with reaching ~60% end-to-end. And even that counts fixing any valid vulnerability the agent turns up; landing the specific target vulnerability stays much lower.
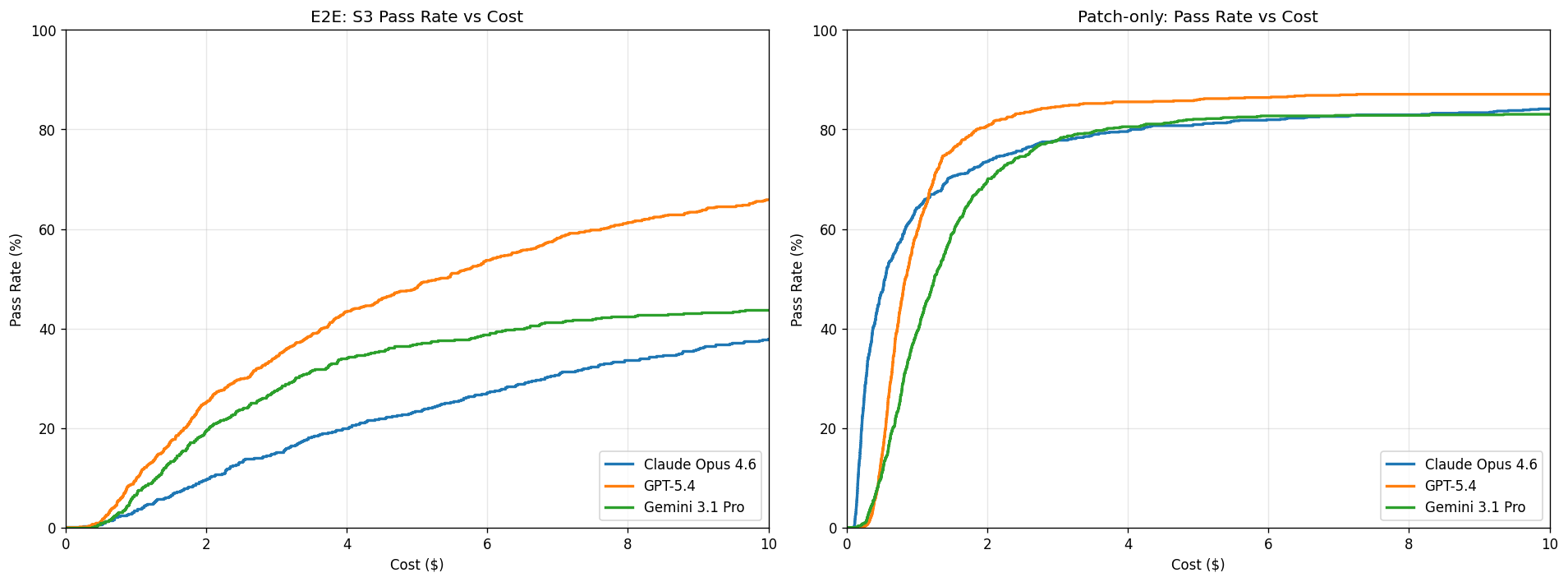
Why this matters.
CyberGym-E2E makes one thing measurable and concrete: today’s frontier agents are frequently able to produce a passing fix once the vulnerability is localized, and the larger gap is about autonomous discovery — a gap the newest models are closing quickly. For defenders, that’s an actionable signal: automated end-to-end remediation could accelerate triage and patching, with human review still in the loop, since not every passing patch is a clean fix. The benchmark contributes to both sides of the responsible-development equation: it gives defenders a realistic, execution-grounded way to measure how much an AI agent can do across the full lifecycle, and it gives model developers a way to track these capabilities where the stakes are unusually high.
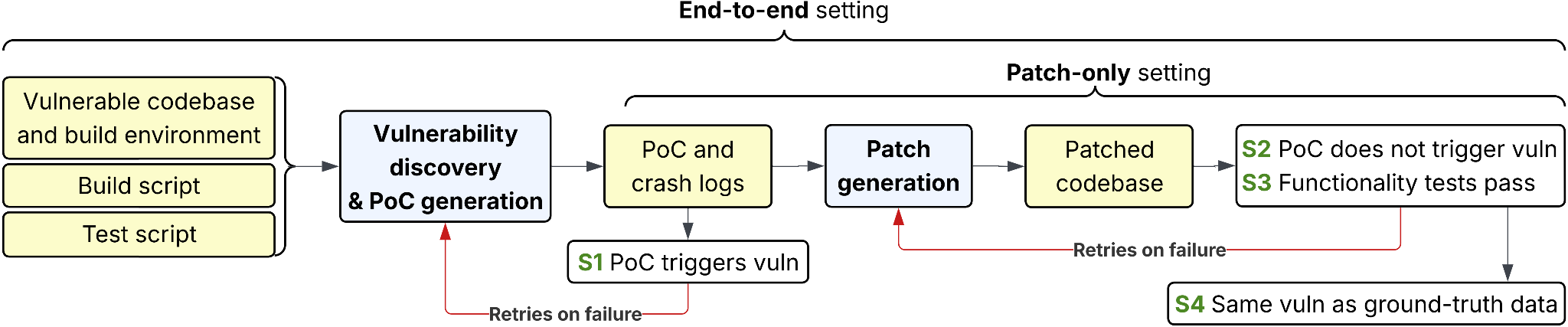
How it works.
Each task gives the agent a vulnerable codebase, build scripts, and test scripts. In the end-to-end setting, all ground-truth data is withheld and the agent must discover the vulnerability, craft a proof-of-concept input, and produce a patch — mirroring a real security researcher’s workflow. Outputs run through four cumulative validation stages: S1, the PoC crashes the unpatched build; S2, the patch fixes that crash; S3, the patched project still passes its functionality tests; and a diagnostic S4 that checks whether the agent fixed the specific ground-truth vulnerability rather than a different valid one it happened to find.
Agents discover alternative vulnerabilities.
There’s a consistent gap between S3 (tests pass) and S4 (the patch fixes the original ground-truth vulnerability). This isn’t the agent doing anything wrong — the task never specifies which vulnerability to find, and real projects contain multiple vulnerabilities. While exploring, agents frequently discover and patch a perfectly valid vulnerability that simply isn’t the one in our ground-truth data. S3 counts those as the successes they are; S4 is a finer-grained diagnostic that tells us how often the agent converged on the specific intended vulnerability, which is the harder target. One promising direction: instruct agents to keep searching after fixing their first vulnerability — enumerating and patching all discoverable vulnerabilities rather than stopping at the first success.
Alternative and shallow patches.
A vulnerability can often be fixed in many different ways, and we observe that many successful agent patches address the same root cause as the ground-truth patch but at a different location. This justifies grading behaviorally rather than by patch similarity, which would falsely reject most legitimate fixes. However, we also observe a small fraction of patches are shallow, inserting a defensive guard at the sanitizer-reported crash frame while leaving the underlying defect untouched. This suggests that agent-produced patches should be treated as candidates for further review rather than drop-in fixes. In this work we focus on verifiable, execution-based judging, so shallow patches that pass all validation stages are still counted as successful; incorporating an additional LLM-based judge to analyze patch quality would be a useful complement.
For more information about CyberGym-E2E, read the blog and paper, along with the benchmark’s website:
Agentic AI Summit 2026 (More Featured Speakers Announced, Limited Number of Tickets Left, and Startup Spotlight Applications Now Open!)

Save the date! The Agentic AI Summit returns to Berkeley on August 1–2, 2026, welcoming 5,000+ expected in-person attendees for two days of insights and innovation. Building on last year’s sold-out success—with 2,000+ in‑person attendees and 40,000+ global livestream participants—the summit will bring together researchers, builders, industry leaders, and the global agentic AI community for keynotes, technical talks and panels, hands-on workshops, live demos, and more!
Full Summit Agenda Now Available!
We are thrilled to announce that the full agenda for the Summit is now available on our website! The Summit is set to feature 200+ speakers across 4 stages, plus 200+ poster presentations during the event! If you’ve been waiting for the schedule to come out before grabbing your tickets, now is the time to take a look and secure your spot!
In addition, we are excited to showcase our expanded list of speakers for the Summit! We are honored to have such a great group of academics, founders, executives, and investors participate in this year’s event, and more will be announced soon!

🎟️ Early‑Bird Pricing (Limited Capacity)
A limited number of early‑bird tickets are still available:
Standard Early-Bird: $399
Apply to the Startup Spotlight
Building the future of Agentic AI? We’re looking for you.
We are excited to announce that applications are now open for the Startup Spotlight at the Agentic AI Summit! Selected startups will have the opportunity to showcase their products and innovations to researchers, founders, engineers, investors, industry leaders, and policymakers from across the AI ecosystem. Apply to showcase your product and innovation!
Applications will be reviewed on a rolling basis, so we encourage interested teams to apply as soon as possible. The deadline to apply is Monday, July 6, at 11:59 PM PT.
You can also learn more about the Summit, the full agenda, and our event sponsors by reading Professor Dawn Song’s recent LinkedIn and Twitter/X updates:
Sponsorship Opportunities
Partner with us to shape the future of Agentic AI. If you’re interested in sponsoring the summit, please complete the sponsorship application form. Sponsorship opportunities are limited and reviewed/allocated on a rolling basis, so we encourage you to apply early.

Trends This Week

In recent research, Anthropic analyzed about 400,000 Claude Code sessions from roughly 235,000 users between October 2025 and April 2026 to study how agentic coding work is divided between humans and AI. According to the company, a typical session saw users make about 70% of planning decisions, while Claude made about 80% of the execution decisions. Anthropic found that task-specific expertise affected outcomes more than formal coding background: novice-rated sessions reached verified success 15% of the time, while intermediate-and-above sessions reached verified success 28–33% of the time. Claude performed more work per prompt for more expert users, rising from about five actions and 600 words of output per prompt in novice sessions to about 12 actions and 3,200 words in expert sessions. Among code-producing sessions, users in non-software occupations reached verified success rates within 7 percentage points of software-related occupations.
Google DeepMind published an AI Control Roadmap for securing advanced AI agents used inside Google, noting that AI agents could create $2.9 trillion in U.S. economic value by 2030. The roadmap adds system-level security on top of model alignment and traditional safeguards such as sandboxing, endpoint security, and prompt-injection resistance. It treats untrusted internal agents as potential insider threats, uses trusted AI supervisors to monitor agent reasoning, actions, and plans, and maps controls to model capabilities, including detection-evasion risk and potential harm. DeepMind says lower-risk actions can be handled through delayed review and remediation, while higher-risk actions may require real-time prevention or blocking. The company also said it has analyzed one million coding-agent tasks to inform an internal monitoring prototype and a live monitor for Gemini Spark, the company’s most recent agentic AI release.
OpenAI reported a novel, near-autonomous science workflow with chemistry startup Molecule.one, connecting GPT-5.4 to Maria, an agentic AI system integrated with a high-throughput laboratory. The system generated research proposals, designed experiments, analyzed experimental results, and proposed follow-up experiments, while human chemists remained involved in steering, proposal selection, plan corrections, lab operations, and validation. OpenAI said the project produced a lab-validated improvement in a medicinal chemistry reaction after 10,080 automated experiments, with human chemists later confirming the result in bench-scale testing. The company framed the result as an example of AI systems assisting across more of the scientific research loop, while noting that the work was not fully autonomous and still requires broader testing and independent replication.
Last week, DeepSeek became China’s most valuable AI startup after raising more than $7.4 billion in its first funding round at a valuation above $50 billion. The round included major Chinese investors, with Tencent reportedly investing around $1.5 billion and battery maker Contemporary Amperex Technology putting in about $740 million. Founder Liang Wenfeng reportedly contributed around $3 billion and retained control through a structure in which most outside investors put capital into a limited partnership he manages, with a five-year lockup. DeepSeek plans to use the capital for artificial intelligence research and development, expanded computing infrastructure, and agentic AI tools, while continuing to pursue artificial general intelligence and open-source technology.
Don’t miss the developments shaping Agentic AI. Subscribe for weekly coverage of groundbreaking research, emerging trends, and critical insights across Agentic AI and the broader AI landscape.
