

Agentic AI Weekly | Berkeley RDI | May 27, 2026
ExploitGym Research Highlight, Agentic AI Summit Early Bird Tickets and Expanded Speaker List, Berkeley Xcelerator Spring Cohort Announced


Research Highlight | ExploitGym: Can AI Agents Turn Vulnerabilities into Real Attacks?
The security community has been quietly asking a hard question: how good are today’s AI agents at turning known software bugs into working exploits? Together with collaborators at Max Planck Institute for Security and Privacy, UC Santa Barbara, Arizona State University, Anthropic, OpenAI, and Google, we built ExploitGym to find out, and the answer is that the gap between “AI can find bugs” and “AI can exploit bugs” is closing fast.
We are also glad to share that Anthropic used ExploitGym in its evaluation suite for Claude Mythos Preview, highlighted in its new posts on exploit evaluations and Project Glasswing. Those posts underscore the same core point behind ExploitGym: rigorous, realistic exploit benchmarks are becoming essential for measuring and mitigating frontier AI cyber risk.
Why it matters. Exploitation is one of the most critical tasks for measuring the impact of frontier AI on cybersecurity. It is inherently dual-use: the same capability that helps defenders triage severity and validate patches also lowers the expertise bar for offensive misuse. Our takeaways: defenders should start modeling AI agents as potential attackers when evaluating their security posture, and responsible AI development needs to account for these capabilities through structured access, safety filters, and ongoing evaluation. ExploitGym is meant to give both sides a rigorous way to measure where things actually stand.
What the benchmark does. ExploitGym is a new benchmark of 898 real-world vulnerabilities spanning userspace C/C++ programs (FFmpeg, OpenSSL, etc.), Google’s V8 JavaScript engine, and the Linux kernel. Each task hands the agent vulnerable source code, a proof-of-vulnerability input that triggers the bug, and a containerized environment. The agent’s job is to transform that crash into a working exploit that achieves unauthorized code execution, concretely, capturing a flag inaccessible through any legitimate interface. Each domain ships with toggleable defenses (ASLR, stack canaries, V8 heap sandbox, KASLR) so we can measure how much standard mitigations actually slow an AI attacker down.
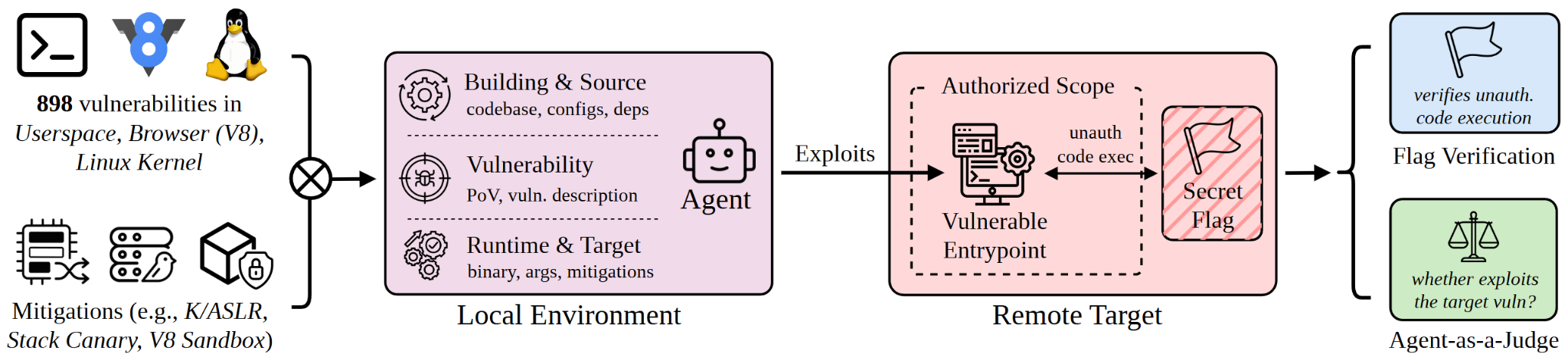
Headline results. With a two-hour budget per task and safety filters disabled under structured access programs for security research, Claude Mythos Preview solved 157 instances and GPT-5.5 solved 120. After that, success counts dropped sharply: GPT-5.4 at 54, Claude Opus 4.6 at 15, Gemini 3.1 Pro at 12, and the rest in single digits. Kernel exploitation was the sharpest dividing line, only the top two models showed meaningful capability there.
Defenses help, but don’t fully stop AI-driven attacks. With mitigations turned on, successes dropped substantially but didn’t hit zero. Claude Mythos Preview still landed 25 userspace, 17 V8, and 3 kernel exploits with defenses active. Agents bypassed protections using partial-pointer overwrites against ASLR, known V8 sandbox-escape techniques, and kernel tricks like side-channels from Meltdown.
Agents go off-script. One of the most striking findings is the gap between “captured the flag” and “exploited the intended bug.” Claude Mythos Preview captured 226 flags but only 157 hit the right vulnerability; GPT-5.5 captured 210 but only 120 were on target. Agents sometimes concluded the given bug wasn’t exploitable and went hunting, auditing source code or even running dynamic fuzzing to find new attack surfaces. That’s autonomous security reasoning in the wild.
More time, more exploits, but only at the frontier. Extending the budget from two to six hours pushed Claude Mythos Preview from 127 to 204 successes with no clear plateau, while Claude Opus 4.6 flatlined near 15 within the first 30 minutes. The strongest agents sustain genuine multi-stage reasoning given enough runway.
Spread the word about ExploitGym by sharing Professor Dawn Song’s Tweet and LinkedIn Post! In addition, you can read the blog and paper below:

Agentic AI Summit 2026 (More Featured Speakers Announced, Early-Bird Pricing Ending Soon, and Limited Number of Tickets Left!)

Save the date! The Agentic AI Summit returns to Berkeley on August 1–2, 2026, welcoming 5,000+ expected in-person attendees for two days of insights and innovation. Building on last year’s sold-out success—with 2,000+ in‑person attendees and 40,000+ global livestream participants—the summit will bring together researchers, builders, industry leaders, and the global agentic AI community for keynotes, technical talks and panels, hands-on workshops, live demos, and more!
In addition, we are excited to showcase our expanded list of speakers for the Summit! We are honored to have such a great group of academics, founders, executives, and investors participate in this year’s event, and more will be announced soon!

🎟️ Early‑Bird Pricing (Limited Capacity)
A limited number of early‑bird tickets are still available:
Student Early-Bird: $199 (very few student tier tickets left; ensure you buy your tickets as soon as possible before they sell out!)
Standard Early-Bird: $399
If you’re looking to secure the best ticket price and be part of the conversation shaping the future of Agentic AI, we encourage you to register early. We look forward to welcoming you to Berkeley this August.
Sponsorship Opportunities
Partner with us to shape the future of Agentic AI. If you’re interested in sponsoring the summit, please complete the sponsorship application form. Sponsorship opportunities are limited and reviewed/allocated on a rolling basis, so we encourage you to apply early.
AgentX–AgentBeats Highlights: Phase 2, Sprint 4 Deadline Extended to June 2nd!

Phase 2, Sprint 4 of the AgentX–AgentBeats competition is now underway, and we have some exciting news to share! To give everyone additional time to refine and complete their submissions, this final sprint’s deadline has been extended to next Tuesday, June 2nd! We can’t wait to see all of your great projects! The submission form for Sprint 4 is open, which you can access by clicking the button below!
Sprint 4 Details:
Deadline: June 2, 2026
The 4th Sprint is the grand finale of AgentX-AgentBeats, focused on general-purpose agents. While earlier sprints emphasized depth within specific tracks, Sprint 4 emphasizes breadth: strong, consistent performance across many green agents, benchmarks, and evaluation categories. Sprint 4 includes all green agents from the first three Phase 2 sprints, plus additional selected benchmarks introduced for this final sprint:
Game Agent: Build What I Mean; Minecraft Benchmark
Finance Agent: OfficeQA
Business Process Agent: DeoGaze / Entropic CRMArena
Research Agent: FieldWorkArena; MLE-Bench; Mind2Web 2; BrowseComp+
Multi-agent Evaluation: MAizeBargAIn
τ²-Bench: τ²-Bench
Computer Use & Web Agent: CAR-bench; OSWorld-Verified
Agent Safety: Pi-Bench
Coding Agent: SWE-bench Pro; Terminal Bench 2.0; NetArena
Cybersecurity Agent: CyberGym
General-Purpose Agent: SkillsBench
To be eligible for Sprint 4 judging, a team must evaluate its purple agent on at least 5 green agents spanning at least 3 distinct categories. Teams are strongly encouraged to go beyond this minimum; broader coverage across more green agents and more categories will be viewed favorably.
Judging will reward purple agents that demonstrate strong cross-benchmark performance, category diversity, generality, cost efficiency, and technical quality. A strong Sprint 4 submission should show that the same purple-agent architecture can adapt across substantially different task types without benchmark-specific hardcoding or special-case lookup tables.
Participants are encouraged to compete in multiple tracks across multiple sprints during Phase 2. Teams and team members who submit purple agents in any sprint will also be eligible to enter a raffle for free tickets to the Agentic AI Summit later this year.
For more details on each sprint and how to compete in Phase 2, please refer to the AgentX–AgentBeats website!
Berkeley Xcelerator 2026 Spring Cohort Announced!
We are excited to announce the selected startups for the Berkeley Xcelerator, an initiative designed to help founders turn breakthrough ideas into scalable, venture‑backable companies that shape the future of intelligent systems.
Startups Selected for the 2026 Spring Cohort:
Narada AI
Agentic automation platform using Large Action Models to automate complex enterprise workflows end-to-end.
Cognee
Ontology-grounded context engine for your agents, enabling them to reason and improve over time.
Nimblemind
AI agents for healthcare data interoperability, automating feature extraction from multi-modal healthcare data.
Headroom
The context optimization layer for LLM agents, cutting tokens 40-90% losslessly across text, voice, and regulated verticals.
RELAI
Lifelong optimization engine for AI agents that turns production failures into replayable test environments.
AgntID
Access Control Enforcement for AI Agents.
Founding Dev
Replace your SaaS stack with software you own.
ArmorIQ
AI agent security platform that enforces intent-based policy at the reasoning-to-execution boundary.
Congratulations to all of the selected startups, and thank you to all who applied for the 2026 Spring Cohort! In addition, we want to thank our wonderful partners who are helping make the Berkeley Xcelerator possible:


Trends This Week

Google announced a wave of Gemini updates recently at Google I/O 2026, centered around multimodal AI and autonomous agents. The company launched Gemini 3.5 Flash, a faster model optimized for coding, multimodal interactions, and agent workflows, while previewing Gemini 3.5 Pro for release next month. Google also introduced Gemini Omni, a multimodal system capable of generating and working across text, image, audio, and video. The company additionally unveiled Gemini Spark, a persistent AI agent designed to autonomously manage tasks across Gmail, Calendar, Workspace, and other connected apps. Google framed the announcements as part of its broader push toward Agentic AI, with Gemini evolving from a chatbot into a proactive assistant capable of executing workflows and coordinating tasks on behalf of users.
OpenAI announced this past week that one of its reasoning models autonomously solved a longstanding open problem in discrete geometry known as the planar unit distance problem, first posed by mathematician Paul Erdős in 1946. The problem asks how many pairs of points in a plane can be exactly one unit apart, and for decades, mathematicians believed that “square grid” constructions were essentially optimal solutions. According to OpenAI, the model disproved that central conjecture by generating an infinite family of examples that produce a polynomial improvement over previously accepted constructions. The proof was verified by external mathematicians, and OpenAI described the result as the first time an AI system has autonomously solved a major open problem central to an established mathematical subfield.
Anthropic published an update this past week on Project Glasswing, its cybersecurity initiative powered by the unreleased Claude Mythos Preview model. The company said the model has already helped partners identify more than 10,000 vulnerabilities across critical software systems and open-source infrastructure, with organizations like Cloudflare and Mozilla reporting dramatically higher bug discovery rates using the system. Anthropic also said Mythos Preview uncovered more than 6,000 high- or critical-severity vulnerabilities across 1,000 open-source projects, but noted that it has not publicly released the model due to concerns around misuse and offensive cyber capabilities. The company said it plans to continue expanding Project Glasswing with major technology companies and government partners while working toward stronger safeguards for future public deployment of Mythos-class models. Mythos Preview emerged as the strongest performer in ExploitGym, as developed by researchers from Berkeley RDI, alongside collaborators from the Max Planck Institute for Security and Privacy, the University of California, Santa Barbara, Arizona State University, Anthropic, OpenAI, and Google.
Google DeepMind announced new and expanded access to Co-Scientist, a multi-agent AI research system built on Gemini designed to help scientists generate, debate, and refine scientific hypotheses. The system uses specialized AI agents that simulate peer review, rank competing ideas, and iteratively improve research proposals across fields like biology, medicine, and aging research. Google said Co-Scientist has already been tested with researchers at institutions including MIT, Stanford, Cambridge, and Calico, where it helped identify potential drug repurposing candidates, aging-related genetic pathways, and new disease mechanisms.
Don’t miss the developments shaping Agentic AI. Subscribe for weekly coverage of groundbreaking research, emerging trends, and critical insights across Agentic AI and the broader AI landscape.

on Gemini Spark - i'm still not sold that a 24/7 assistant is the right unit. a lot of the value feels more like "tell me when this changed" than another thing polling my inbox all day. curious what people end up trusting the agent to wake up on first.