

Agentic AI Weekly | Berkeley RDI | September 17, 2025
New Agentic AI MOOC kicks off, why models hallucinate, and Thinking Machines Lab's potential LLM breakthrough



This week, Berkeley RDI launched its Fall 2025 Agentic AI MOOC with our community of over 25,000 eager learners! On Monday, OpenAI researcher Yann Dubois gave a general overview of LLM agents, explaining pretraining, reasoning, and reinforcement learning, among other key concepts.


This Week’s Lecture: Introduction to Training LLMs for AI Agents
The Training Pipeline
Pretraining: Predict next word on internet (>10T tokens, takes months, > $10M compute cost, bottlenecked by data)
Reasoning RL: Think on questions with objective answers (approx. 1M problems, takes weeks, compute cost >$1M, bottlenecked by RL env and hacks)
Classic Post-Training/RLHF: Max user utility & prefs (approx. 100K problems, takes days, >$100K compute cost, bottlenecked by data and evals)
Pretraining
Goal: teach the model everything in the world
Task: predict the next word
Data: any reasonable data on internet
> 10T tokens (20-40T for Llama 4, 15T for DSv3)
> 20B unique web pages
Key since GPT-2 (2019)
Note: Internet is dirty & not representative of what we want, requires filtering
Post-Training
Problem: Language modeling is not equal to assisting users; language modeling is not what we want
Classic PT/alignment/IF:
Goal: Steer the model to be useful on real-world tasks
Task: Maximize answer preferences of humans
Two main methods: SFT (supervised finetuning) & RL (reinforcement learning)
SFT is either seen as a final stage or a preparation for RL, finetunes the LLM with language modeling of the desired answers
RL’s idea: Maximize desired behavior rather than clone it
Sub-method of RL, RL from Human Feedback (RLHF), maximizes human preference rather than clone their behavior, made ChatGPT
Evaluation
Human evaluation: Have users interact (blinded) with two chatbots, rate which is better (eg, ChatBot Arena); problem is cost & speed.
LLM evaluation: Use LLM instead of human
Shows 98% correlation with ChatBot Arena
<3 min & <$10
Challenge: Spurious correlation


Moving the Needle: The Cloud 100, Why Models Hallucinate, and Thinking Machines Lab’s LLM Breakthrough
Recently, Bessemer Venture Partners released the tenth edition of the Cloud 100, which ranks the world’s top private cloud and AI companies. As expected, AI leaders like OpenAI, Anthropic, and Anysphere dominate the list, showcasing record valuations, compressed time-to-scale milestones, and an increasing talent war. As the report highlights, the future of cloud leadership is inseparable from the pace of AI innovation.
For the third year in a row, OpenAI tops the list, but the biggest mover by ranking was search startup Perplexity, which moved up 59 spots to #26.

Here are some insights from the Cloud 100 Benchmark Report:
🧠 AI companies doubled their share of list value from 21% to 42% in one year
🔒 Private companies are staying private longer
📈 This year’s companies are nearly 20 times the size of their predecessors from a decade ago
This past week, OpenAI researchers Adam Tauman Kalai, Ofir Nachum, Edwin Zhang, and Santosh Vempala (Georgia Tech) released a paper that aims to find out why and when models hallucinate.
The paper argues that LLM hallucinations stem from the statistical structure of training and evaluation, which favors confident guessing over expressing uncertainty. In fact, it was explained that if 20% of birthday facts appear only once in pretraining data, you can expect the end model to hallucinate on at least 20% of birthday facts in the future, which degrades the trustworthiness of the model.
Specifically, the researchers note:
“Binary evaluations of language models impose a false right-wrong dichotomy, award no credit to answers that express uncertainty, omit dubious details, or request clarification.”
— Kalai et al., Why Language Models Hallucinate (2025)
Pretraining inherently produces errors, particularly for rare facts, while post-training benchmarks reinforce overconfidence by penalizing models for saying that they do not know the answer to a question. To solve this problem, the authors propose that “…evaluations explicitly state confidence targets in their instructions, within the prompt (or system message).” This, in turn, would realign the incentive structure of models,
In other news, former OpenAI Chief Technology Officer Mira Murati’s Thinking Machines Lab released preliminary research this week, in which it claims to have made a leap forward in one of LLMs’ most prevalent issues: Nondeterminism.
The team shows that randomness in LLM outputs isn’t irreducible noise, but can be mathematically predicted through hidden correlations and controlled with a new class of “batch-invariant kernels.” According to the researchers, “With these kernels, repeated queries to the same prompt yield identical outputs across runs.”
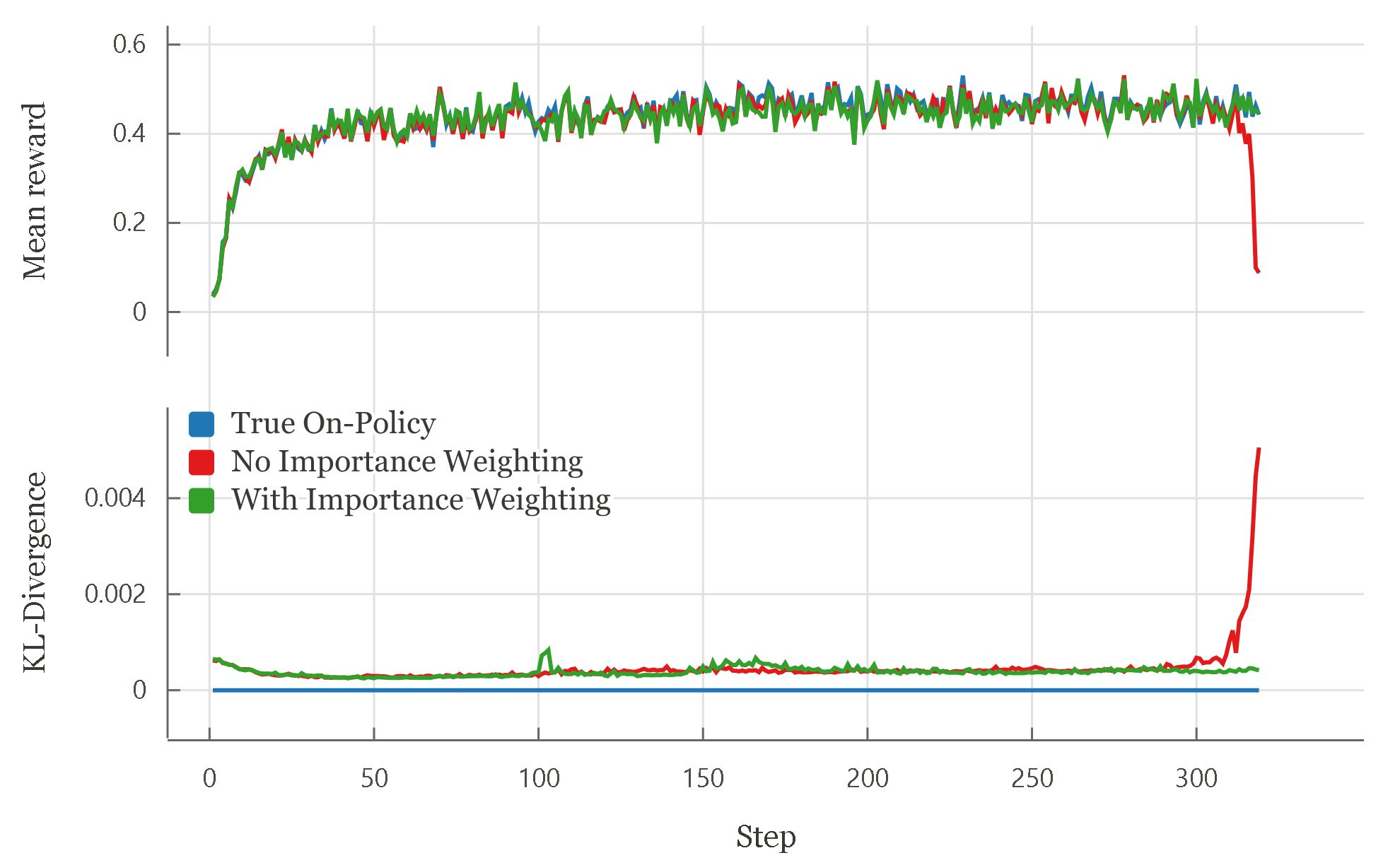
One important consequence of deterministic inference is cleaner, more reliable machine learning experiments, including reinforcement learning. Thinking Machines Lab’s blog demonstrates that when sampling and training numerics are different, what is intended to be on-policy RL behaves off-policy when put into practice, forcing practitioners to either accept instability or apply off-policy corrections (such as importance weighting).
In their RL experiments (Bigmath with a Qwen 2.5‑VL policy), training without off‑policy correction led to reward collapse, while either using importance weighting or making sampler and trainer bitwise identical allowed for stable learning. When sampler and trainer match exactly, the KL divergence is zero, and true on‑policy behavior is restored, as seen in the chart below.
Other Trends This Week:
In a move that could lead to massive changes to how AI models’ training data is acquired, a judge has put Anthropic’s $1.5 billion book piracy settlement on hold. Previously, Anthropic was accused of pirating books for training its models, and the judge believes that the settlement was forced
”down the throats” of authors and now seeks an alternative ruling.Nvidia and OpenAI are reportedly discussing a significant deal to support data center development in the UK, one that could be worth “billions of dollars.” It is expected to be unveiled next week during U.S. President Donald Trump’s state visit to the UK.
Replit, the agentic coding startup that assists users in creating web apps via natural language, raised a $250 million funding round this past week that values the company at $3 billion. The startup reported $150 million in annualized revenue and has now raised a total of around $478 million.
In a sign that there is increasing competition in the inference hardware market, Korea’s FuriosaAI is preparing to raise more than $300 million ahead of its IPO. The company rejected a $800 million takeover bid from Meta earlier this year and has a chip that it claims delivers 2.25 times better inference performance per watt compared with Nvidia’s GPUs.
California’s legislature passed Bill SB 53, an AI safety law that would require large AI labs to disclose their safety practices, protect whistleblowers, and set up “CalCompute,” a public cloud for compute resources. The measure now awaits Governor Gavin Newsom’s decision.
Don't miss the developments shaping Agentic AI. Subscribe for weekly coverage of groundbreaking research, emerging trends, and critical insights across Agentic AI and the broader AI landscape.

Enjoyed accessible intro to Thinking Machines’ Nondeterminism experiments!
You might be interested in sharing the Agentic Internet Workshop with your community. We are convening folks working on AgenticAI Protocols - https://agenticinternetworkshop.org/